
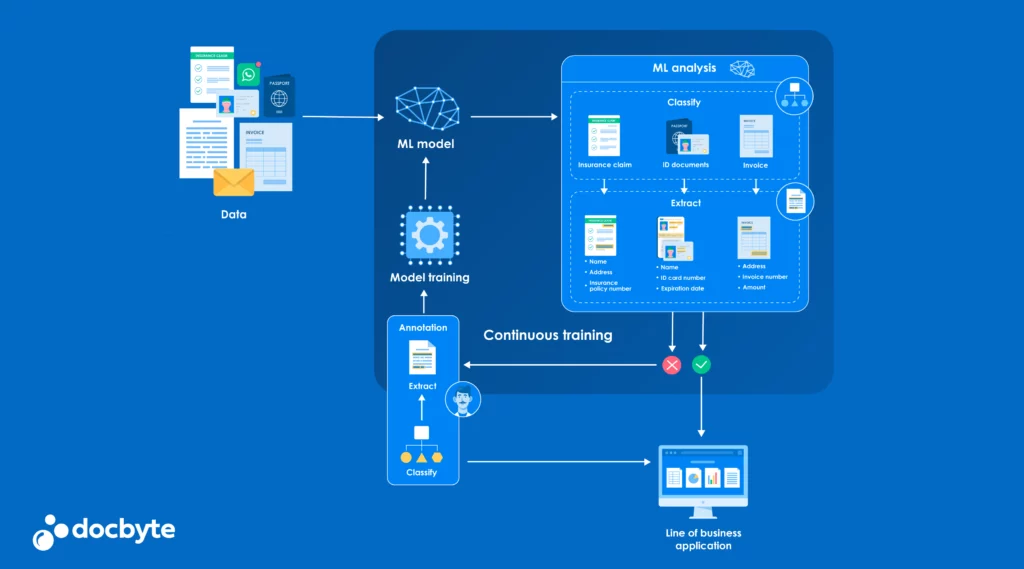
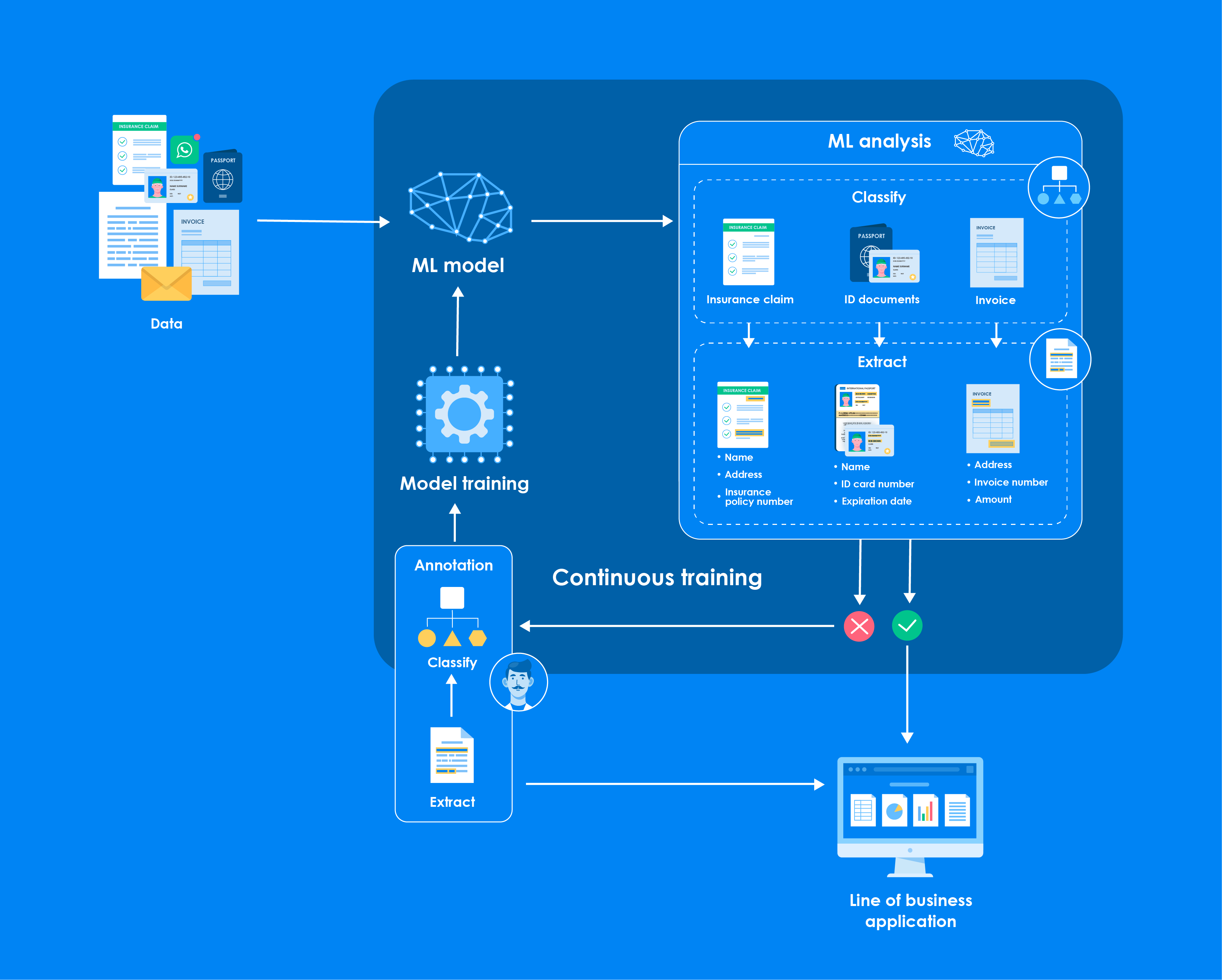
The term ‘continuous training machine learning’ is gaining substantial traction. This powerful technology propels our digital world into the future and significantly impacts how businesses handle their most critical asset: information.
In this deep dive, we will explore the relationship between continuous training machine learning and the archiving of vital documents — unveiling both the opportunities and potential pitfalls in this sophisticated process.
What is Continuous Training Machine Learning?
Before we go into how continuous training machine learning (ML) interfaces with document archiving, we must first comprehend its core principles. Continuous training ML, often described as an ongoing or incremental learning process, allows machine learning models to update and augment themselves as new data becomes available continuously.
This dynamic paradigm is especially suited for scenarios where the data is voluminous and subject to rapid and unpredictable change. By re-training models on the latest data, organisations can enjoy a more accurate and up-to-date representation of the environment the ML model is meant to ‘understand’.
But why is this vital within the context of document archiving? The answer lies in the ability of ML models to identify patterns and extract valuable insights from all the documents and data laid before them—and our documents are our most valuable assets.

ML in Action: Classifying Documents
Document classification – sorting documents into categories based on their content – is a pivotal use case for ML. Continuous training in ML can refine the document classification process with each new piece of data. As documents are archived in a system, they contribute to the ongoing training of the system, making the classification process increasingly accurate over time.
For instance, consider a law firm that must categorise legal briefs, case law, and client correspondence. By implementing continuous training ML techniques, the system can ‘learn’ from the unique features of each type of document, continuously improving its accuracy and efficiency.
ML in Action: Information Extraction
Beyond classifying documents, ML also excels at information extraction, the process of retrieving specific data points from within a document. A financial institution needs to extract customer information from various forms and agreements.
Continuous training ML models can identify and extract customer names, addresses, and other pertinent details, adapting to new document formats as they’re introduced.
This functionality is not only a time-saver but also ensures higher accuracy in data extraction, as the ML model is fine-tuned over time.
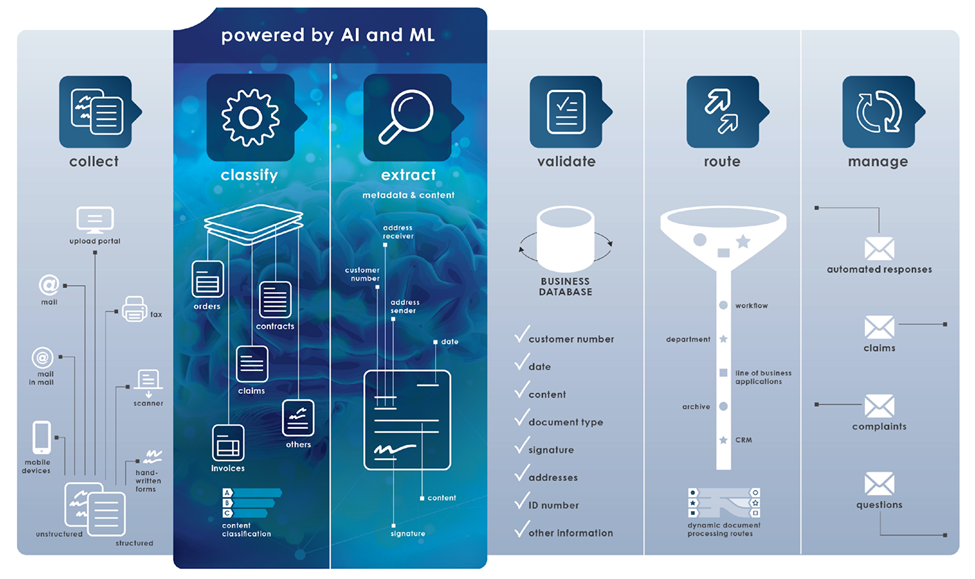
Challenges of ML in Document Archiving
Despite the great promise of ML in document archiving, it’s not without its challenges. One such obstacle is ensuring the security and privacy of archived data. When human lives may rely on the correctness of processed information in documents, such as in the medical field, or when personal data is shared, such as with financial records, the risk of privacy infringement is high.
Moreover, there’s the concern of ‘over-reliance’ on ML. While these systems can become exceedingly adept at their tasks, they are flexible. Errors occur when documents deviate from expected patterns or models misinterpret data. Therefore, it’s essential to communicate document model or data structure changes to your quality control department or the party responsible for the ML system. This way, document classification and extraction can be checked for accuracy.
Common Document Mistakes
Continuing in the vein of potential errors, let’s explore some of the most common mistakes when scanning and archiving customer IDs. With the rise of digital identity verification, ensuring the accuracy of ID scans is crucial. Mistakes such as incomplete scans, poor image resolution, or misalignment during scanning can lead to incorrect or unusable data.
When these errors are fed into an ML system for archiving or analysis, they can propagate inaccuracies, creating a ripple effect of issues throughout the archival process. Therefore, businesses must employ quality control measures in scanning and archiving workflows.
ML with Human Interference
Human intervention often remains essential at the intersection of machine learning and archiving. This human-in-the-loop concept ensures that ML models maintain their learning curves on the correct trajectories. Subject matter experts can play a crucial role in validating ML outputs, correcting errors, and providing feedback that guides the model to make more accurate predictions and decisions.
Another consideration is the regulatory landscape. Compliance officers and legal teams are the gatekeepers who must ensure that document archiving and retrieval processes adhere to the latest regulations.
Benefits of ML in Document Archiving
While there are challenges to implementing these systems, the benefits are significant. ML-driven document archiving streamlines operations reduces manual labour, and improves efficiency. It allows enterprises to harness the power of their data repositories in once-impossible ways, offering insights and trends that lay dormant in unstructured data.
Moreover, the dynamism of continuous training ML keeps businesses adaptable enough to integrate new document types and data formats as they emerge. It transforms document archiving from a static requirement into a strategic asset that fuels business intelligence and innovation.
Embracing the Future
Continuous training in machine learning presents unprecedented opportunities in document archiving and beyond. It promises to transform how we manage the past and shape the future through the insights gained from our vast document collections. However, with great power comes great responsibility. Organisations navigating this space must tread carefully, leveraging the benefits of ML while respecting the pitfalls that it may bring.
For IT specialists and legal minds alike, a proactive and informed approach will be the key to unlocking the full potential of continuous training machine learning in document archiving. By doing so, enterprises will optimise their internal processes. They will also set the stage for a new era of digitised, intelligent archiving that can adapt and grow along with the businesses it serves.




