
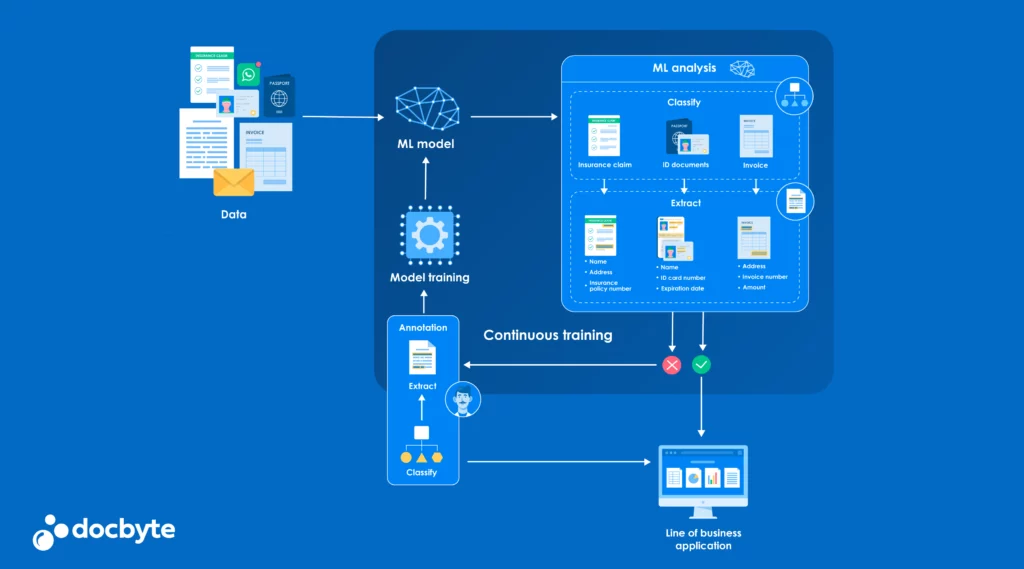
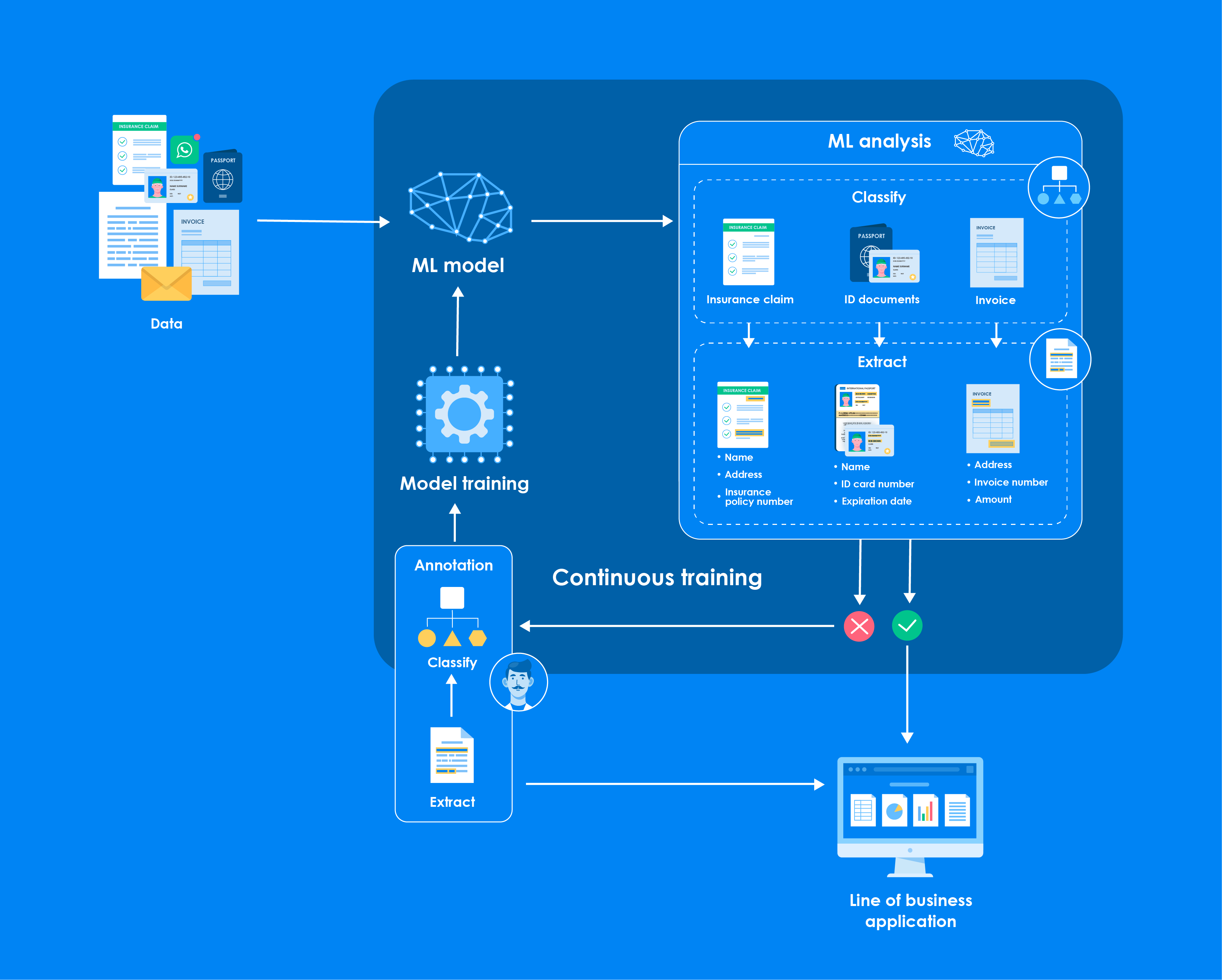
L'expression "apprentissage automatique en formation continue" gagne du terrain. Cette technologie puissante propulse notre monde numérique vers l'avenir et a un impact significatif sur la manière dont les entreprises gèrent leur actif le plus critique : l'information.
Dans cette étude approfondie, nous explorerons la relation entre l'apprentissage automatique en continu et l'archivage de documents vitaux, en dévoilant à la fois les opportunités et les pièges potentiels de ce processus sophistiqué.
Qu'est-ce que l'apprentissage automatique en continu ?
Avant d'aborder la question de l'interface entre l'apprentissage automatique en formation continue et la technologie de l'information et de la communication (TIC), nous allons nous pencher sur les points suivants l'archivage des documentsPour cela, il faut d'abord en comprendre les principes fondamentaux. La formation continue ML, souvent décrite comme un processus d'apprentissage continu ou incrémental, permet aux modèles d'apprentissage automatique de se mettre à jour et de s'enrichir au fur et à mesure que de nouvelles données sont disponibles.
Ce paradigme dynamique est particulièrement adapté aux scénarios dans lesquels les données sont volumineuses et sujettes à des changements rapides et imprévisibles. En entraînant à nouveau les modèles sur les données les plus récentes, les organisations peuvent bénéficier d'une représentation plus précise et plus actuelle de l'environnement que le modèle de ML est censé "comprendre".
Mais pourquoi est-ce vital dans le contexte de l'archivage des documents ? La réponse réside dans la capacité des modèles de ML à identifier des modèles et à extraire des informations précieuses de tous les documents et données qui leur sont présentés - et nos documents sont nos actifs les plus précieux.

ML en action : Classification de documents
La classification des documents, qui consiste à classer les documents dans des catégories en fonction de leur contenu, est un cas d'utilisation essentiel de la ML. La formation continue en ML permet d'affiner le processus de classification des documents avec chaque nouvel élément de données. Au fur et à mesure que les documents sont archivés dans un système, ils contribuent à la formation continue du système, ce qui rend le processus de classification de plus en plus précis au fil du temps.
Prenons l'exemple d'un cabinet d'avocats qui doit classer les mémoires juridiques, la jurisprudence et la correspondance avec les clients. En mettant en œuvre des techniques de formation continue en ML, le système peut "apprendre" à partir des caractéristiques uniques de chaque type de document, améliorant continuellement sa précision et son efficacité.
ML en action : Extraction d'informations
Au-delà de la classification des documents, la ML excelle également dans l'extraction d'informations, c'est-à-dire le processus de récupération de points de données spécifiques à l'intérieur d'un document. Une institution financière doit extraire des informations sur les clients à partir de divers formulaires et accords.
Les modèles de ML à formation continue peuvent identifier et extraire les noms des clients, leurs adresses et d'autres détails pertinents, en s'adaptant aux nouveaux formats de documents au fur et à mesure qu'ils sont introduits.
Cette fonctionnalité permet non seulement de gagner du temps, mais aussi de garantir une plus grande précision dans l'extraction des données, car le modèle ML est affiné au fil du temps.
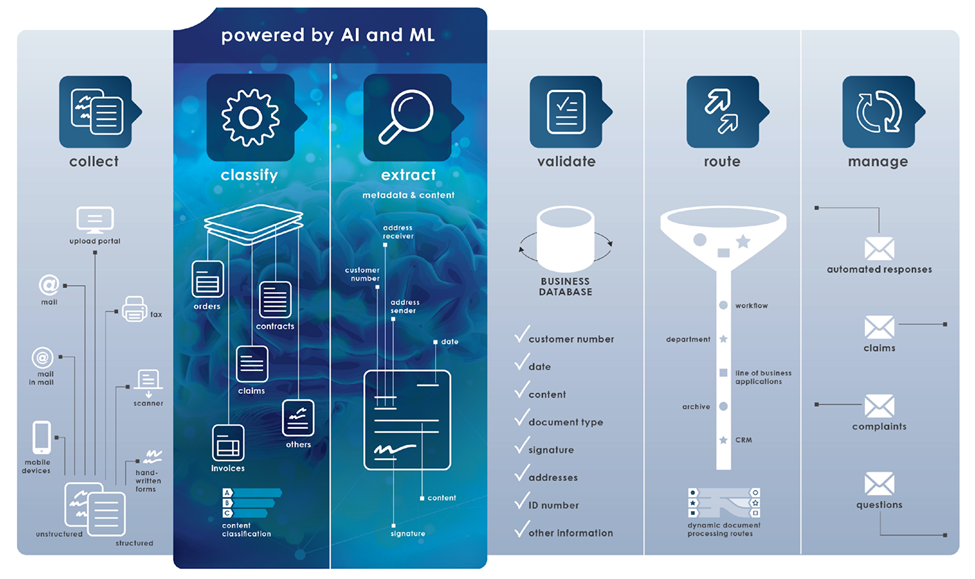
Les défis de la ML dans l'archivage des documents
Malgré les grandes promesses de la ML dans l'archivage des documents, elle n'est pas sans poser de problèmes. L'un d'entre eux consiste à garantir la sécurité et la confidentialité des données archivées. Lorsque des vies humaines dépendent de l'exactitude des informations traitées dans les documents, comme dans le domaine médical, ou lorsque des données personnelles sont partagées, comme dans le cas des dossiers financiers, le risque d'atteinte à la vie privée est élevé.
En outre, il existe un risque de "dépendance excessive" à l'égard de la ML. Bien que ces systèmes puissent devenir extrêmement compétents dans leurs tâches, ils sont flexibles. Des erreurs se produisent lorsque les documents s'écartent des modèles attendus ou que les modèles interprètent mal les données. Il est donc essentiel de communiquer les modifications apportées au modèle de document ou à la structure des données à votre service de contrôle de la qualité ou à la partie responsable du système de ML. De cette manière, la classification et l'extraction des documents peuvent être vérifiées pour s'assurer de leur exactitude.
Erreurs courantes dans les documents
Dans la lignée des erreurs potentielles, examinons quelques-unes des erreurs les plus courantes lors de la numérisation et de l'archivage des pièces d'identité des clients. Avec l'essor de la vérification numérique de l'identité, il est essentiel de s'assurer de l'exactitude des scans de pièces d'identité. Des erreurs telles que des numérisations incomplètes, une mauvaise résolution d'image ou un mauvais alignement lors de la numérisation peuvent conduire à des données incorrectes ou inutilisables.
Lorsque ces erreurs sont introduites dans un système de ML pour l'archivage ou l'analyse, elles peuvent propager des inexactitudes, créant un effet d'entraînement de problèmes tout au long du processus d'archivage. C'est pourquoi les entreprises doivent appliquer des mesures de contrôle de la qualité dans les flux de numérisation et d'archivage.
ML avec interférence humaine
L'intervention humaine reste souvent essentielle à l'intersection de l'apprentissage automatique et de l'archivage. Ce concept d'intervention humaine dans la boucle garantit que les modèles d'apprentissage automatique maintiennent leurs courbes d'apprentissage sur des trajectoires correctes. Les experts en la matière peuvent jouer un rôle crucial en validant les résultats de l'apprentissage automatique, en corrigeant les erreurs et en fournissant un retour d'information qui aide le modèle à faire des prédictions et à prendre des décisions plus précises.
Le paysage réglementaire est un autre élément à prendre en compte. Les responsables de la conformité et les équipes juridiques sont les gardiens qui doivent s'assurer que les processus d'archivage et de récupération des documents respectent les dernières réglementations.
Avantages de la ML dans l'archivage des documents
Bien que la mise en œuvre de ces systèmes présente des difficultés, les avantages sont considérables. L'archivage de documents basé sur la ML rationalise les opérations et réduit les coûts. travail manuelet améliore l'efficacité. Il permet aux entreprises d'exploiter la puissance de leurs référentiels de données d'une manière autrefois impossible, en offrant des perspectives et des tendances qui sommeillaient dans les données non structurées.
De plus, le dynamisme de la formation continue ML permet aux entreprises de rester suffisamment adaptables pour intégrer de nouveaux types de documents et de formats de données au fur et à mesure de leur apparition. L'archivage des documents passe ainsi d'une exigence statique à un atout stratégique qui alimente l'intelligence économique et l'innovation.
Faire face à l'avenir
La formation continue en matière d'apprentissage automatique offre des possibilités sans précédent dans le domaine de l'archivage des documents et au-delà. Elle promet de transformer la façon dont nous gérons le passé et façonnons l'avenir grâce aux connaissances acquises à partir de nos vastes collections de documents. Cependant, un grand pouvoir s'accompagne d'une grande responsabilité. Les organisations qui naviguent dans cet espace doivent avancer avec prudence, en tirant parti des avantages de l'apprentissage automatique tout en respectant les pièges qu'il peut entraîner.
Pour les spécialistes de l'informatique comme pour les juristes, une approche proactive et informée sera la clé pour libérer tout le potentiel de l'apprentissage automatique en formation continue dans l'archivage des documents. Ce faisant, les entreprises optimiseront leurs processus internes. Elles ouvriront également la voie à une nouvelle ère d'archivage numérisé et intelligent, capable de s'adapter et de se développer en même temps que les entreprises qu'il sert.


